On many conferences where AI, ML or data science is mentioned, a simple dataset is used to underpin the storyline of the sessions. The Titanic dataset is such a relatively small and simple example. Until now a Fact Oriented Model was absent. So, let's see how we can build one out of the dataset by verbalizing it.
Here's the first Data Science example page we'll use to find the data, some description and build our information model.
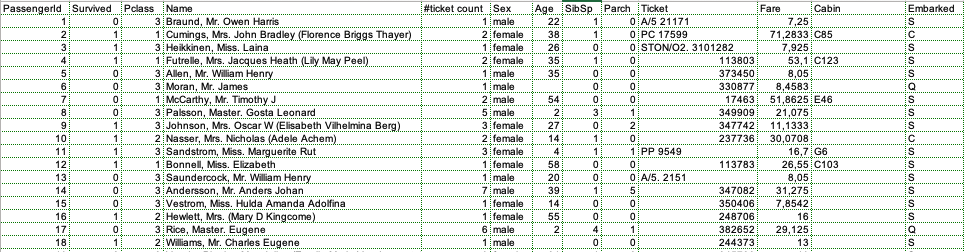
When opening the data file (CSV or XLS) there's something very obvious that jumps out. The passengers are numbered by Passenger ID, and they all have a name. That'll be the start of the first set of fact expressions:
Passenger Name "Passenger 1252 is called Sage, Master. William Henry." "Passenger 160 is called Sage, Master. Thomas Henry." "Passenger 558 is called Robbins, Mr. Victor." "Passenger 951 is called Chaudanson, Miss. Victorine."
Apparently, not all passengers are registered to embark in the same port as the ticket is registered for. Therefor the single letter "C" which is short for Cherbourg, we state separate facts:
Embarking
"Passenger 1034 embarked in Cherbourg."
Related to these passengers, we can easily spot some trivial data which is obviously related to them:
Passenger Age "Passenger 1252 has the age of 14,5 years."
Passenger Gender "Passenger 160 is male."
Passenger Hometown
"Passenger 160 is from the hometown Peterborough, Cambridgeshire, England."
And as we all know by the history books, a lot of people lost their lives. The dataset has this fact listed as a number where 0 means they've died, and 1 means they survived. For readability we simply verbalize these facts as:
Passenger Survived
"Passenger 160 survived? No."
Then the data becomes a little nebulous, hence the difficulties in dataset cleansing and understanding. We find fare prices. The data doesn't explain in which currency this is listed. Neither does the dataset explain if this is the price per passenger or per full ticket. Studying the numbers, we can derive the fact that this must be a price per person listed on a ticket. Similarly, tickets seem to be listing a single class value per individual ticket. Here are the facts we can find for tickets:
Fare "Fare for ticket PC 17608 is 262.375."
Passage Class
"Ticket CA. 2343 is for class 3."
Ticket Boarding "Ticket CA. 2343 boards in Southampton." Ticket Destination "Ticket CA. 2343 is set for destination Jacksonville, Florida, US.
Ticket for Cabin "Passengers with ticket PC 17608 are assigned to cabin B57." "Passengers with ticket PC 17608 are assigned to cabin B59." "Passengers with ticket PC 17608 are assigned to cabin B61." "Passengers with ticket PC 17608 are assigned to cabin B63." "Passengers with ticket PC 17608 are assigned to cabin B66."
Tickets are registered for one or more passengers:
Ticket for Passenger "Ticket CA. 2343 lists passenger 1252
The data also lists the family constellations, by listing two numbers for parents/children and sibling/spouse. Also the total amount of passengers per ticket is mentioned:
Parents/Children "Passenger 1034 has 3 parents/children on board."
Sibling/Spouce
"Passenger 1034 has 1 spouse or sibling on board."
Ticket Count "Ticket PC 17608 is for 7 passengers.
The following information is derivable or added using the wiki pages to list the ports in the order the Titanic traveled and where the ports are. These are not from the dataset themselves, but make it easier to comprehend:
Port Country "Ports Queenstown lies in Ireland."
Titanic Port Order
"Boarding 1 happened in Southampton."
"Boarding 2 happened in Cherbourg."
"Boarding 3 happened in Queenstown."
Family Size
; this is calculated by counting the passenger themselves plus the sibling/spouce, plus parents/children "The family size of passenger 1034 is 5.
Now when classified and qualified into an information model, a visualization of can be made:
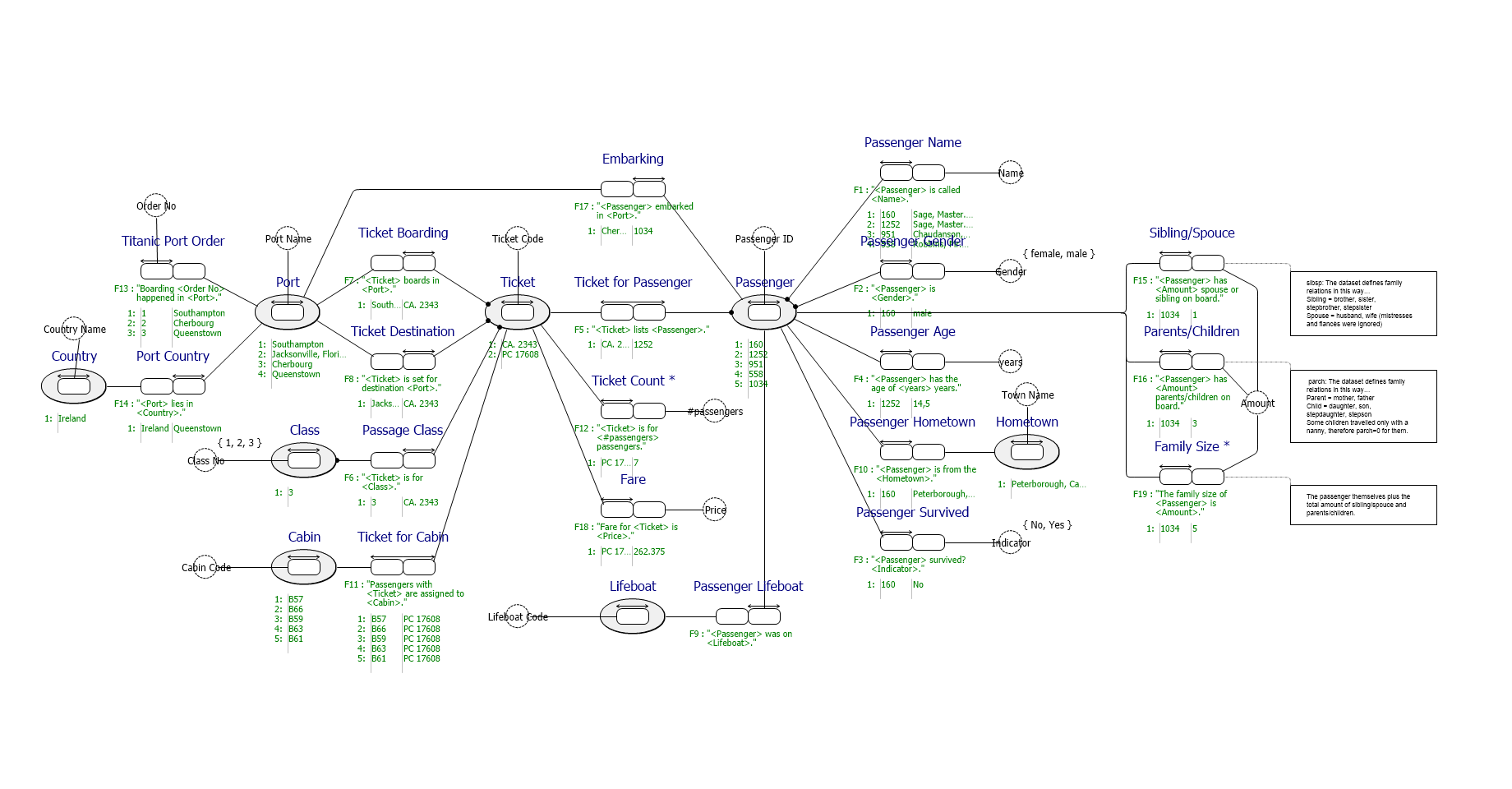
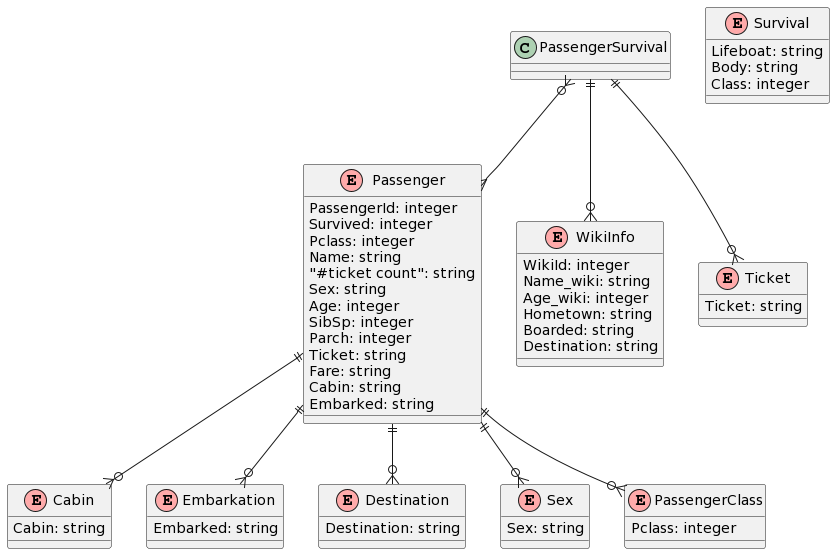
For those who appreciate a more condensed visualization, an ERD diagram may be more helpful. CaseTalk will generate this automatically. To many, this illustrates how nebilous a simple dataset can be. There are many relations which are not instantly obvious from just looking at rows and columns full of data:

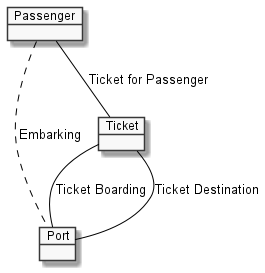
Finally, the most high level diagram which shows barely any details of any meaning illustrates the broad information in the raw data file:
Having a solid Fact Oriented Model may clarify the structures in the dataset, and by having this data verbalized makes everyone can verify if assumptions made on this data are accurate or not. Without facts, any AI/ML model will be based on information which is only in the mind of the data scientist. To make AI/ML transparent and achieve responsible AI, we need to make raw source data verified and document it in an way everyone can understand.
Download the source model here from our Github account.
ChatGPT
Since ChatGPT became a big hit, I revisited this article to see what it could do to help understand the original dataset. I've uploaded the CSV file by simply pasting it and asking it to list the columns and provide a description. It did wonderfully:
PassengerId: Unique identifier for each passenger (integer)Survived: Survival status (0 = did not survive, 1 = survived) (integer)Pclass: Passenger class (integer)Name: Passenger's name (string)#ticket count: Number of tickets associated with the passenger (string)Sex: Passenger's sex (string)Age: Passenger's age (integer)SibSp: Number of siblings/spouses aboard the Titanic (integer)Parch: Number of parents/children aboard the Titanic (integer)Ticket: Ticket number (string)Fare: Fare paid for the ticket (string)Cabin: Cabin number (string)Embarked: Port of embarkation (string)WikiId: Wikipedia ID (integer)Name_wiki: Passenger's name on Wikipedia (string)Age_wiki: Age of the passenger as mentioned on Wikipedia (integer)Hometown: Passenger's hometown (string)Boarded: Location where the passenger boarded the Titanic (string)Destination: Passenger's intended destination (string)Lifeboat: Lifeboat number (string)Body: Identification number of the recovered body (string)Class: Class of the passenger (integer)
And it even provided a note that these were to be taken with a pinch of salt, since it could be wrong. But when asked to also provide an ER Diagram in PlantUML notation, it showed an alarming lack of cohesion. It impressive it came up with an almost(!) working script, but it then becomes hard to verify since it lacked the attributes and verbalization.
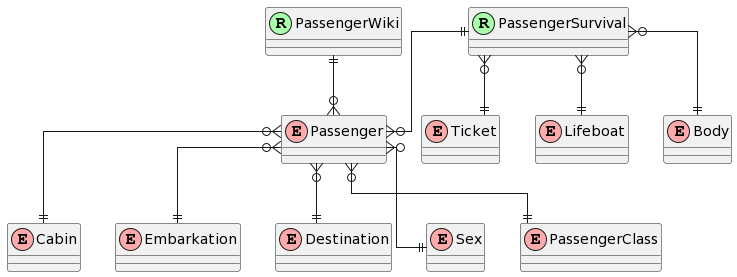
To clarify the entities a little more, I asked to include the columns/attributes in the diagram. It made more sense, but did you also see how the number of entities changed as well? It appears that at the time of writing, the actual meaning and how data relates still needs to be defined by human intellect. Comparing it with our manual efforts, the results are poor and inconsistent in time. The generative aspects for textual definitions seem very usable as a starting point to discuss with the domain experts.