Understanding Modeling Terminology
Untangling the vocabulary of data and information modeling
The Terminology Jungle
If you've spent any time in the data modeling space, you've likely encountered a bewildering array of terms: data model, conceptual model, logical model, physical model, concept model, semantic model, information model, fact-oriented model. These terms are sometimes used interchangeably, sometimes mean completely different things depending on who's speaking, and often cause more confusion than clarity.
This article aims to untangle these terms, trace their historical origins, and explain why the distinctions matter—especially as organizations grapple with integrating systems across departments and making sense of decades of accumulated data.
AI Needs More Than a Glossary
The semantic grounding problem that glossaries, ontologies, and vector databases can't solve on their own
You've probably noticed the pattern by now. You feed your data to an AI, ask it a question, and get an answer that's technically plausible but semantically wrong. The AI confuses "customer" in your sales system with "client" in your support tickets. It hallucinates relationships between fields that share similar names but mean entirely different things. Ask the same question twice with slightly different phrasing, and you get contradictory responses.
Welcome to semantic drift—the silent killer of AI reliability.
Understanding before Data
Why Data Modeling Must Start with Human Understanding
A Conversation on Information Modeling, AI, and the Real Challenge of Enterprise DataIn a recent conversation with a data professional exploring database development tools, Marco Wobben offered a perspective that cuts straight through the noise surrounding modern data projects. With over 25 years in information modeling, he's seen the same pattern repeat: technology advances rapidly, yet the biggest failures trace back to something very human.
- Beyond the Technical
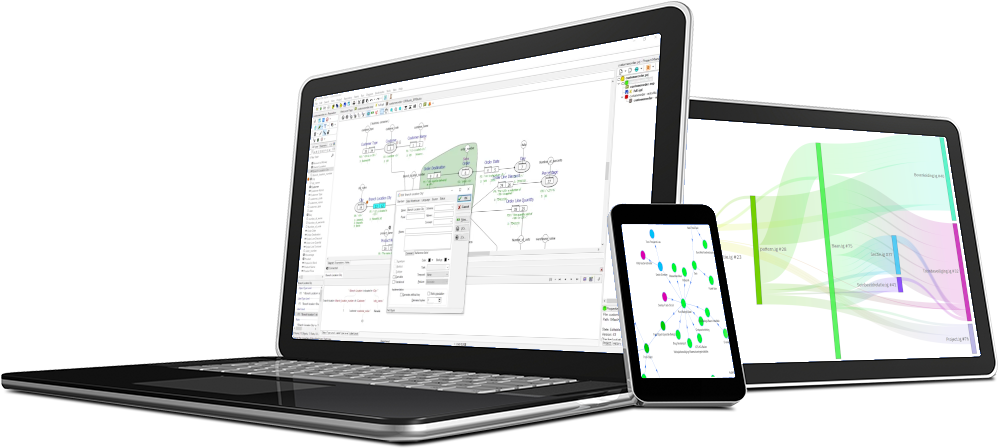
- Data Explorer
- The Illusion of 'Data-Driven'
- Population on a Map
- SIG 2024
- Pilot FOM in Rotterdam
- Modeling Entities
- CaseTalk Bookmarks
- Python DataClass
- Legal Articles and Information
- Story telling
- DotRunner (Free)
- Event Modeling
- Puppy Tricks
- Abstract Model
- The why and how
- CaseTalk partners HvA, HR and HU
- Congratulations!
- Entities from thin air
- Data Vault Coloring
- Concepts and Containers
- Temporal, Transitional and Localization Annotations
- Bi-Weekly Ticket Newsletter
- Congratulations!
- Security by design
- Data Centricity
- Use Case - ProRail
- Use Case - AFM
- Black Lives Matter
- Computable Award 2007 [NL]
- Type level modeling is (too) easy
- Generic "Customer"
- Temporal & Transitional Modeling
- GDPR by design
- Wikipedia
- Add language, add knowledge
- Presenting the new FCO-IM Book
- Arriving for DMZ 2015
- Ready for DMZ
- Killing three birds with one stone
- Fresh supply of FCO-IM Books
- Guido Bakema to be ambassador for CaseTalk
- Share your work
- Cooperation HAN and ICT-companies
- Cooperation HAN and BCP Software
- Cooperation Four Points and BCP Software