July 2018
With the recent rush for GDPR compliance, we wanted to show you how simple the extension of new data model requirements can be in CaseTalk. It's a simple two-step procedure to mark all elements sensitive to privacy violations as such. But first, the definition of GDPR:
The General Data Protection Regulation (GDPR) (EU) 2016/679 is a regulation in EU law on data protection and privacy for all individuals within the European Union (EU) and the European Economic Area (EEA). It also addresses the export of personal data outside the EU and EEA areas. The GDPR aims primarily to give control to citizens and residents over their personal data and to simplify the regulatory environment for international business by unifying the regulation within the EU.
Superseding the Data Protection Directive 95/46/EC, the regulation contains provisions and requirements pertaining to the processing of personally identifiable information of individuals (formally called data subjects in the GDPR) inside the European Union, and applies to all enterprises, regardless of location, that are doing business with the European Economic Area. Business processes that handle personal data must be built with data protection by design and by default, ... [source: wikipedia]
The definition includes "by design and by default" which emphasizes the importance of having your data model correctly designed, and all privacy-sensitive information elements clearly marked as such. Since there are many approaches to specify the privacy-sensitive nature of data, we took a simplified approach. By this example, you should be capable to implement your own GDPR compliant markers to your data models.
Within CaseTalk we define a new custom attribute category called "Source". We mark that category available to various levels of information elements and structures. That way, we can apply GPDR markers to the entire model, a diagram, fact types or expressions.
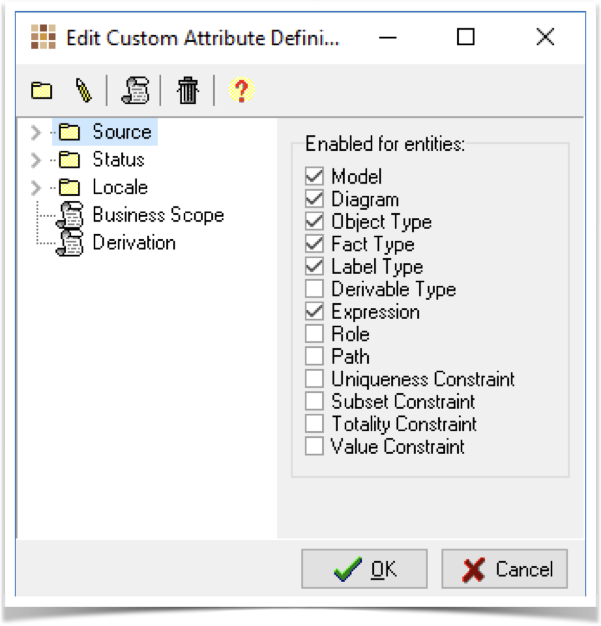
Within the Source category, we declare the custom attribute as an Option list containing these options: Restricted, Private, Public.
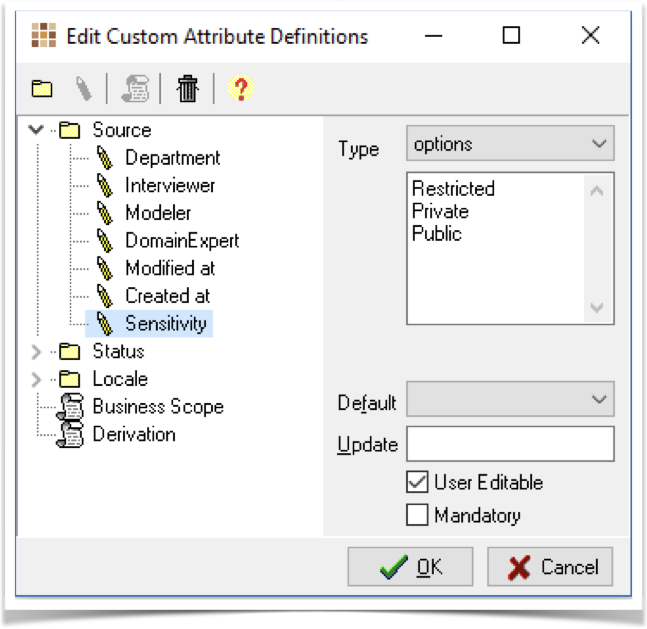
Once defined, we can now use these markers to enhance our data model. Whenever we open a property dialog for the Model; Diagram; Fact Type; or Expression, the source category will be displayed. Within the source tab, we are able to mark the GDPR sensitivity level.
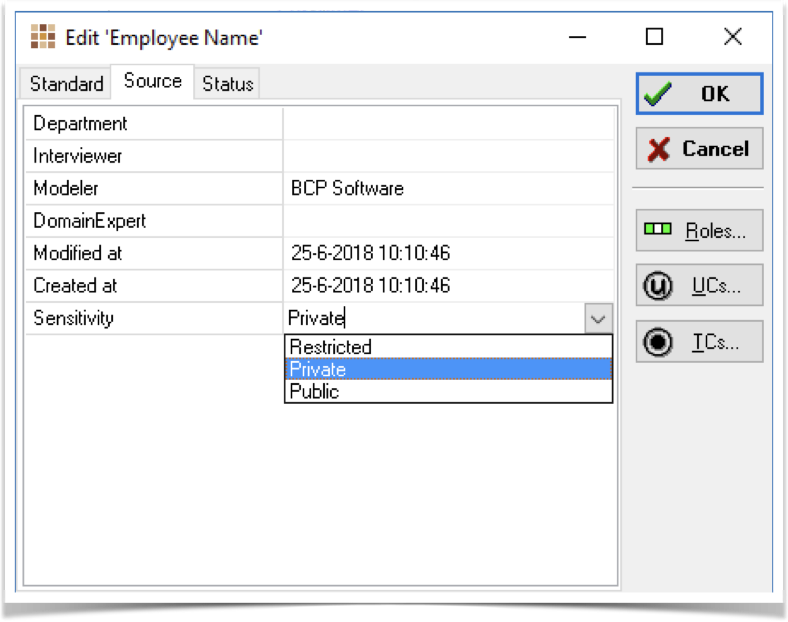
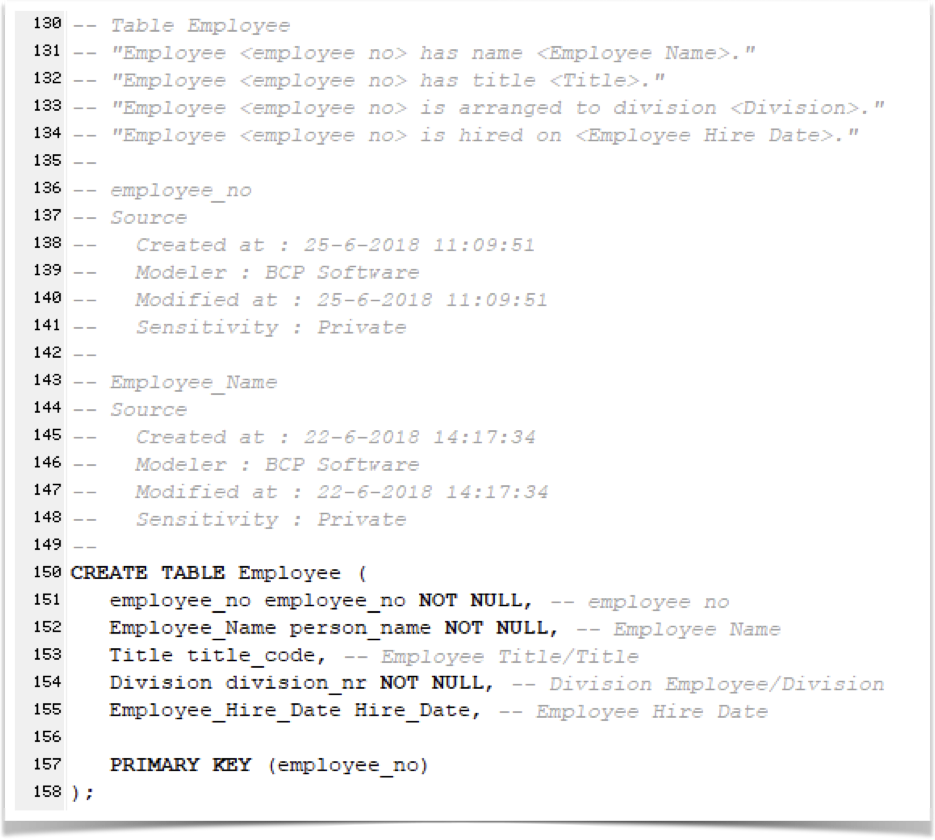
When deriving technical artifacts from your data model, these privacy-sensitive markers are transported into those as well. For example, the above marked Employee_Name is clearly stated to be set to a "Sensitivity: private" in the SQL generated from the data model.
Conclusion
As you've seen, adding GDPR compliance to your design is easily set up. By adding custom attribute definitions to your models or custom annotations, you are able to comply with any new ruling that is or will be applicable to your business and data models. Your data model complies by design and your systems might comply by default, but that's another story. ;-)