In response to Python's growing popularity among developers, CaseTalk extends its support to help developers align their work with business requirements. We've harnessed the power of Python's dataclasses to bridge this gap. However, dataclasses alone offer limited support for the rich conceptual information models in CaseTalk. To overcome this limitation, we've incorporated metadata support.
metadata
In Python, metadata serves as a means to provide runtime information, essential for supporting third-party tools. Within CaseTalk, we utilize metadata to annotate and capture information not natively supported by dataclasses. Our CaseTalkBaseClass is your key to unlocking the potential of metadata, allowing you to evaluate information and maintain essential constraints from your conceptual model.
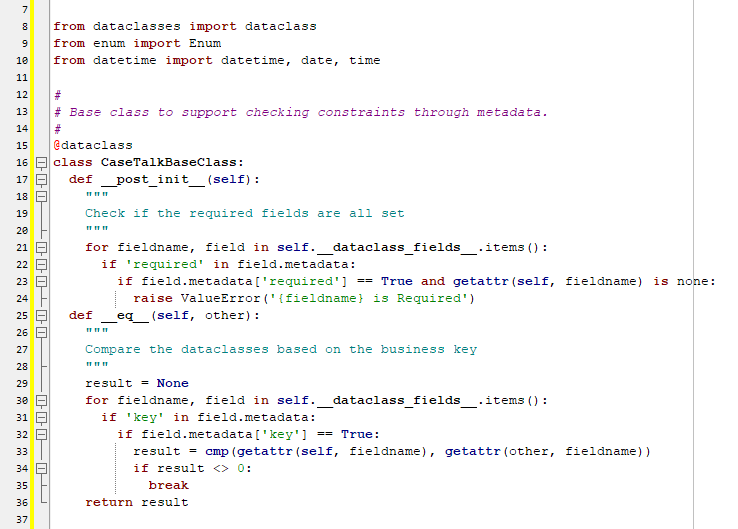
With the groundwork laid for constraint evaluation, we can now move forward with the generation of Python code.
dataclass

Our generated code consists of various sections for each class. These classes are derived from the information model. Custom attributes are documented within the class, surrounded by """ comments. These annotations serve as invaluable documentation for Python developers.
The fields within the dataclasses include artificial keys, default values, and metadata that convey additional requirements, such as "id," "required," or "key," indicating the natural business key. The Express method transforms these fields' data into natural language, preserving the integrity of the original information model.
Conclusion
This groundbreaking Python code generator empowers developers by bringing the vital knowledge from the information model to their fingertips. By harmonizing development with business requirements and leveraging the high-quality knowledge encapsulated in CaseTalk's conceptual models, we bridge the gap between developers and the world of business knowledge.